前言
2021.10.29,spring cloud 以前只零碎用过几个组件,这次系统学一遍
环境:SpringBoot 2.4.2 、SpringCloud 2020.0.1 、SpringCloud Alibaba 2021.1、JDK 8、MYSQL 5.7
这个系列只讲实现,基本不会深入原理。
代码仓库 hystrix-demo 分支 :Learning Use Cases/Spring Cloud Demo - Gitee.com
官网文档:Home · Netflix/Hystrix Wiki (github.com)
本文介绍 spring cloud 断路器 Hystrix。Hystrix 虽然官方已经不更新了,但是公司有一个维护的项目用了这个。不过以后新项目估计也不用了。
- Hystrix 是一个用于处理分布式系统的 延迟 和 容错 的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等。
- Hystrix 能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
其中,觉得最常用的还是下面这个应用场景:
Hystrix 可以在某个服务单元发生故障后,向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常。
Hystrix 可以用在每一个服务模块,不过一般用在客户端,也就是流量入口处做了限制即可。
在开始代码之前,先介绍概念。
雪崩、熔断、降级
服务雪崩
一个服务失败,导致整条链路的服务都失败的情形,我们称之为 服务雪崩
例如,下面几个服务:
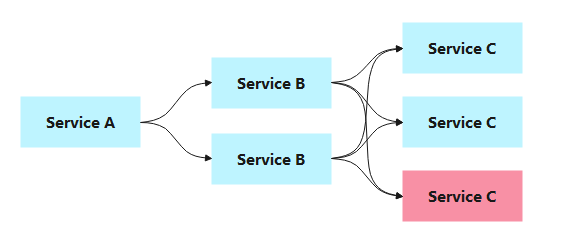
两个 Service B 、三个 Service C 进行负载均衡,刚好可以处理请求。
如果发生意外导致
Service C崩了,例如遇到:硬件故障、流量激增(异常流量,重试加大流量)、缓存穿透(一般发生在应用重启,所有缓存失效时,以及短时间内大量缓存失效,使请求直击后端服务,造成服务提供者超负荷运行,引起服务不可用)、程序BUG(内存泄漏,JVM 长时间 FullGC)、同步等待等导致
Service B偶尔调用宕机Service C不可用,转而加大其他两个Service C压力,最后都不可用最后整条服务调用链路全部崩盘。
应对服务雪崩,各个问题都有对应的方法:
- 硬件故障:多机房容灾、异地多活等。
- 流量激增:服务自动扩容、流量控制(限流、关闭重试)等。
- 缓存穿透:缓存预加载、缓存异步加载等。
- 程序BUG:修改程序bug、及时释放资源等。
- 同步等待:资源隔离、MQ 解耦、不可用服务调用快速失败等。资源隔离通常指不同服务调用采用不同的线程池;不可用服务调用快速失败一般通过熔断器模式结合超时机制实现。
仔细观察,其实大多数的雪崩问题起因,都可以通过架构方式解决。但是如果真的出现了服务宕机,需要有可以保证整体系统仍然稳定运行。
服务熔断
服务熔断是应对雪崩效应的一种微服务链路保护机制。
当调用链路的某个微服务不可用或者响应时间太长时,会进行服务熔断,不再有该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
这样就可以保证服务故障不进行蔓延,导致雪崩。
熔断其实是一个框架级的处理,那么这套熔断机制的设计,基本上业内用的是 断路器模式 。状态转换图如下所示:
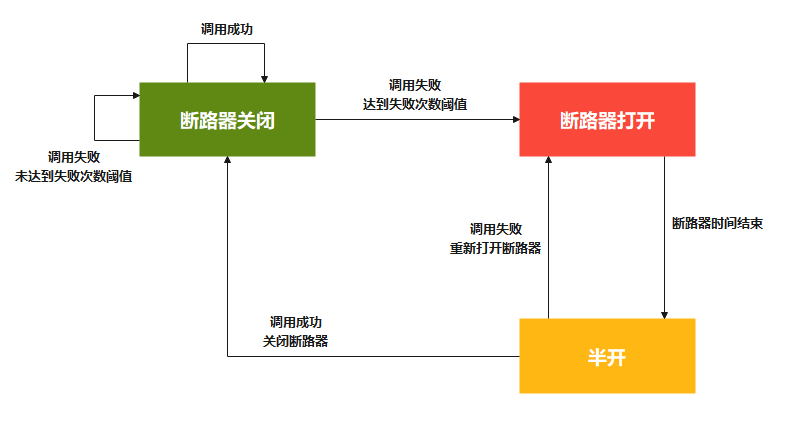
详细的配置后续再讲。
服务降级
这里先解释熔断和降级的区别:
- 服务熔断一般是某个服务(下游服务)故障引起;服务降级一般是从整体负荷考虑。
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分);降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
- 实现方式不太一样,服务降级具有代码侵入性(由控制器完成/或自动降级),熔断一般称为自我熔断。
有点抽象啊。。。再详细一点。
服务熔断 :当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,可以将一些 不重要 或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用。
服务降级的主要类型如下:
- 超时降级 :主要配置好超时时间和超时重试次数和机制,并使用异步机制探测恢复情况
- 失败次数降级 :主要是一些不稳定的API,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
- 故障降级 :如要调用的远程服务挂掉了(网络故障、DNS故障、HTTP服务返回错误的状态码和RPC服务抛出异常),则可以直接降级
- 限流降级 :当触发了限流超额时,可以使用暂时屏蔽的方式来进行短暂的屏蔽
所以,其实可以发现,服务熔断其实可以试为服务降级的一种,服务熔断导致服务不可用。
概念讲完了。。。

看完服务降级,其实个人觉得,服务降级的场景在一般的公司中没有什么应用场景,至少在我们公司目前是肯定用不到。
为什么要等到服务降级,既然在代码设计期就能预设到故障场景,为什么不提前解决而等到发生故障再降级。。大佬们的思想还领略不到。。。。
Hystrix 入门使用
pom 依赖引入:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.2.9.RELEASE</version>
</dependency>
启动类添加注解:
@EnableHystrix
客户端使用 openfegin 调用时,使用了 hystrix 则需要配置文件开启:
# 开启 hystrix
feign:
hystrix:
enabled: true
然后在开始前,先说明测试服务关系:
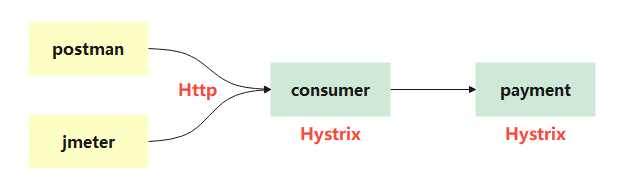
Hystrix 测试分为包括:payment 服务超时、payment 宕机、consumer 故障
响应超时、系统出错
异常情况:payment 响应超时或者处理请求出错,这里需要先设置方法处理最长时限,超过了时限则需要有兜底方法处理,做服务降级 fallback
payment 服务 controller 里,测试超时方法:
@HystrixCommand(fallbackMethod = "timeoutFallback", commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000")
})
@ResponseBody
@GetMapping(value = "timeout")
public Result<Payment> timeout() throws InterruptedException {
log.info("接到请求,开始处理。。。。");
Thread.sleep(5000);
log.info("处理结束,可以返回了。。。。");
return Result.<Payment>builder().code(CodeEnum.SUCCESS.code).message("操作成功,延时5秒").build();
}
fallbackMethod = "timeoutFallback" 配置了对应的 应变计划 方法:
/**
* hystrix fallback方法,超时触发
*/
public Result<Payment> timeoutFallback(){
return Result.<Payment>builder().code(CodeEnum.ERROR.code).message("调用超时,触发 hystrix fallback 方法").build();
}
直接用 postman 调用 payment 超时方法:
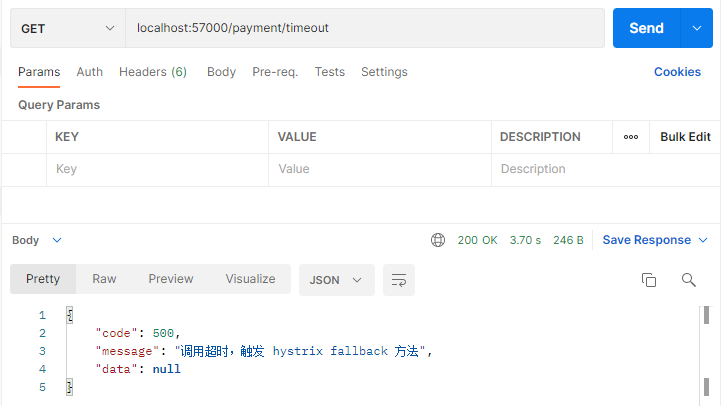
将延时 5 秒方法稍作修改,改为系统处理出错,结果不变。
表示默认
@HystrixCommand注解,可以处理自行捕捉excepition,返回fallback方法
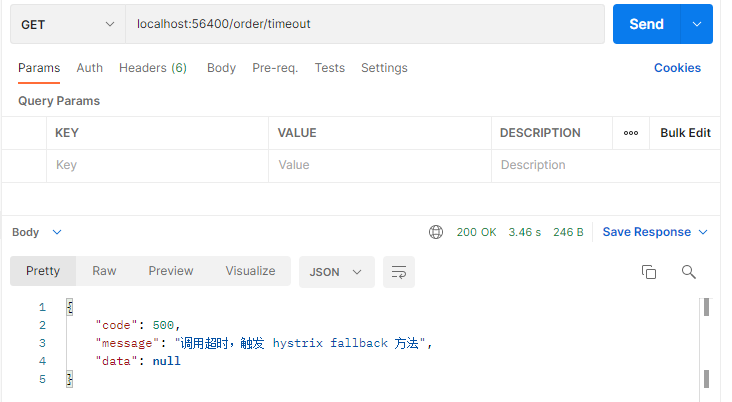
请求超时
异常情况:consumer 设定了请求最长等待时间,服务端处理超时,立刻调用 fallback 方法,不再继续等待
调用出错也和上面一样,哪个服务出错就用哪个 fallback.
consumer 客户端调用:
@HystrixCommand(fallbackMethod = "timeoutFallback", commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1000")
})
@ResponseBody
@GetMapping(value = "timeout")
public Result<PaymentDTO> timeout() {
return paymentServiceFegin.timeout();
}
同样准备 fallback 方法:
public Result<PaymentDTO> timeoutFallback(){
return Result.<PaymentDTO>builder().code(CodeEnum.ERROR.code).message("consumer 请求超时或错误,触发 hystrix fallback 方法").build();
}
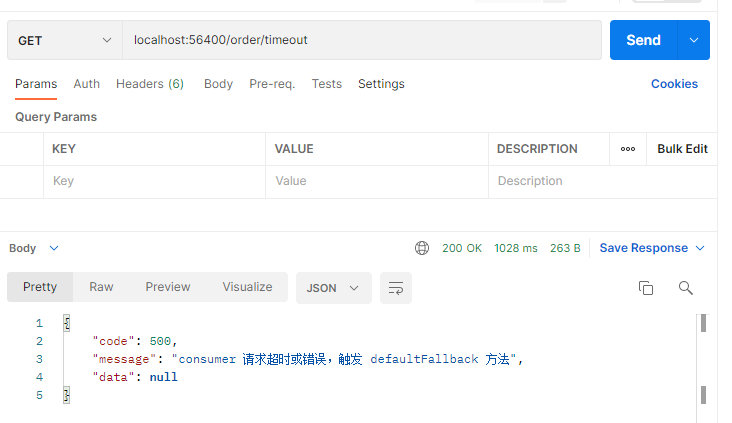
客户端等待 1 秒、服务端最长处理时间 3 秒、方法线程等待 5 秒,实际调用结果:
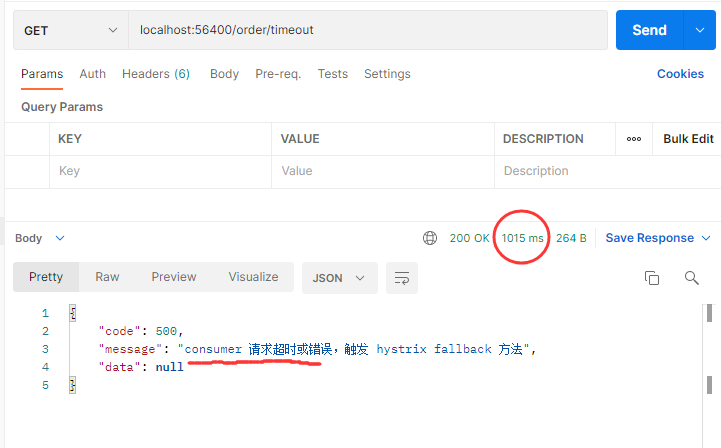

可以发现:
客户端等待 1秒后停止继续调用,并且服务端也不继续执行代码,并没有完整执行方法内代码
熔断、恢复
异常情况:服务调用出错频率过高,则触发熔断,立刻调用 fallback 方法,过一段时间自动恢复。
payment 准备熔断方法:20秒内,如果请求次数超过 10次、或者失败率达到 60%,则触发断路器
代码:
@HystrixCommand(fallbackMethod = "defaultFallback", commandProperties = {
// 是否开启断路器
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"),
// 请求次数
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),
// 时间窗口期
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "20000"),
// 跳闸失败率
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "60"),
})
@ResponseBody
@GetMapping(value = "getById")
public Result<Payment> getById(Long id) throws Exception {
if (id > 0){
return Result.<Payment>builder().code(CodeEnum.SUCCESS.code).message("查询成功,参数:" + id).build();
}else {
throw new Exception("抛出已知异常,通过 fallback 返回");
}
}
准备 fallback 方法:
public Result<Payment> defaultFallback(Long id){
return Result.<Payment>builder().code(CodeEnum.ERROR.code).message("payment 服务触发熔断").build();
}
这里说明下,fallback 方法参数要与 HystrixCommand注解方法一致,不然会找不到。
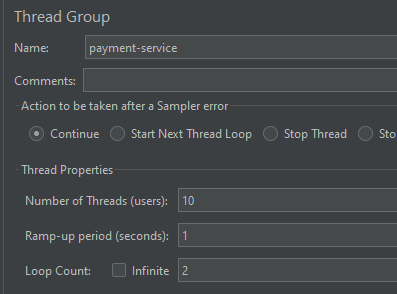
开始测试,首先 jmeter 1秒内请求20次,并且是异常请求:
立刻使用 postman 进行正常请求:
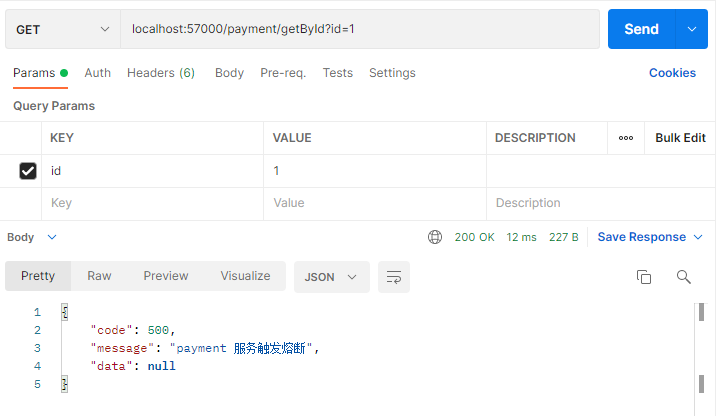
过个 5 秒再请求一次:
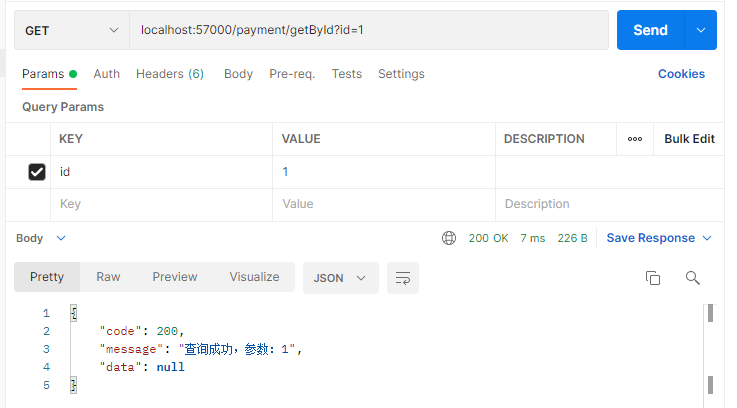
更精确的测试就不做了,反正就这么个情况。
其他说明:
- 熔断器内部有个 平均故障处理时间,达到该时间则进入半熔断状态。
- 熔断器只能加在服务端,不能写在客户端。
服务宕机
现在引入 consumer ,通过 openFegin 进行调用,若 payment 整个服务停了。
其实什么都不需要做,这个就相当于调用出错,一行代码不改,最后调用了客户端的 fallback 方法。
常用注解及详解
DefaultProperties
可以在 controller 上全局添加默认 fallback 方法:
@DefaultProperties(defaultFallback = "defaultFallback")
@Slf4j
@RestController
@RequestMapping(value = "/order")
public class OrderController extends BaseController{
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1000")
})
@ResponseBody
@GetMapping(value = "timeout")
public Result<PaymentDTO> timeout() {
return paymentServiceFegin.timeout();
}
}
在父类上面统一方法:
public class BaseController {
public Result<PaymentDTO> defaultFallback(){
return Result.<PaymentDTO>builder().code(CodeEnum.ERROR.code).message("consumer 请求超时或错误,触发 defaultFallback 方法").build();
}
}
除了特殊需要指定的方法,其他就能全局配置。
HystrixCommand
commandKey
配置全局唯一标识服务的名称,比如,库存系统有一个获取库存服务,那么就可以为这个服务起一个名字来唯一识别该服务。
如果不配置,则默认是 @HystrixCommand 注解修饰的函数的函数名。
groupKey
一个比较重要的注解,配置全局唯一标识服务分组的名称。
比如,库存系统就是一个服务分组。通过设置分组,Hystrix会根据组来组织和统计命令的告、仪表盘等信息。
Hystrix命令默认的线程划分也是根据命令组来实现。
默认情况下,Hystrix会让相同组名的命令使用同一个线程池,所以我们需要在创建Hystrix命令时为其指定命令组来实现默认的线程池划分。
此外,Hystrix还提供了通过设置threadPoolKey来对线程池进行设置。建议最好设置该参数,使用threadPoolKey来控制线程池组。
fallbackMethod
@HystrixCommand 注解修饰的函数的回调函数
@HystrixCommand 修饰的函数必须和这个回调函数定义在同一个类中,因为定义在了同一个类中。
commandProperties
常用的也就是测试代码中那几个,对照表看大佬们的总结:
Command属性主要用来控制HystrixCommand命令的行为,它主要分下面的类别:
1、Execution:用来控制HystrixCommand.run()的执行 execution.isolation.strategy:该属性用来设置HystrixCommand.run()执行的隔离策略。默认为THREAD。 execution.isolation.thread.timeoutInMilliseconds:该属性用来配置HystrixCommand执行的超时时间,单位为毫秒。 execution.timeout.enabled:该属性用来配置HystrixCommand.run()的执行是否启用超时时间。默认为true。 execution.isolation.thread.interruptOnTimeout:该属性用来配置当HystrixCommand.run()执行超时的时候是否要它中断。 execution.isolation.thread.interruptOnCancel:该属性用来配置当HystrixCommand.run()执行取消时是否要它中断。 execution.isolation.semaphore.maxConcurrentRequests:当HystrixCommand命令的隔离策略使用信号量时,该属性用来配置信号量的大小。当最大并发请求达到该设置值时,后续的请求将被拒绝。
2、Fallback:用来控制HystrixCommand.getFallback()的执行 fallback.isolation.semaphore.maxConcurrentRequests:该属性用来设置从调用线程中允许HystrixCommand.getFallback()方法执行的最大并发请求数。当达到最大并发请求时,后续的请求将会被拒绝并抛出异常。 fallback.enabled:该属性用来设置服务降级策略是否启用,默认是true。如果设置为false,当请求失败或者拒绝发生时,将不会调用HystrixCommand.getFallback()来执行服务降级逻辑。
3、Circuit Breaker:用来控制HystrixCircuitBreaker的行为。 circuitBreaker.enabled:确定当服务请求命令失败时,是否使用断路器来跟踪其健康指标和熔断请求。默认为true。 circuitBreaker.requestVolumeThreshold:用来设置在滚动时间窗中,断路器熔断的最小请求数。例如,默认该值为20的时候,如果滚动时间窗(默认10秒)内仅收到19个请求,即使这19个请求都失败了,断路器也不会打开。 circuitBreaker.sleepWindowInMilliseconds:用来设置当断路器打开之后的休眠时间窗。休眠时间窗结束之后,会将断路器设置为“半开”状态,尝试熔断的请求命令,如果依然时候就将断路器继续设置为“打开”状态,如果成功,就设置为“关闭”状态。 circuitBreaker.errorThresholdPercentage:该属性用来设置断路器打开的错误百分比条件。默认值为50,表示在滚动时间窗中,在请求值超过requestVolumeThreshold阈值的前提下,如果错误请求数百分比超过50,就把断路器设置为“打开”状态,否则就设置为“关闭”状态。 circuitBreaker.forceOpen:该属性默认为false。如果该属性设置为true,断路器将强制进入“打开”状态,它会拒绝所有请求。该属性优于forceClosed属性。 circuitBreaker.forceClosed:该属性默认为false。如果该属性设置为true,断路器强制进入“关闭”状态,它会接收所有请求。如果forceOpen属性为true,该属性不生效。
4、Metrics:该属性与HystrixCommand和HystrixObservableCommand执行中捕获的指标相关。 metrics.rollingStats.timeInMilliseconds:该属性用来设置滚动时间窗的长度,单位为毫秒。该时间用于断路器判断健康度时需要收集信息的持续时间。断路器在收集指标信息时会根据设置的时间窗长度拆分成多个桶来累计各度量值,每个桶记录了一段时间的采集指标。例如,当为默认值10000毫秒时,断路器默认将其分成10个桶,每个桶记录1000毫秒内的指标信息。 metrics.rollingStats.numBuckets:用来设置滚动时间窗统计指标信息时划分“桶”的数量。默认值为10。 metrics.rollingPercentile.enabled:用来设置对命令执行延迟是否使用百分位数来跟踪和计算。默认为true,如果设置为false,那么所有的概要统计都将返回-1。 metrics.rollingPercentile.timeInMilliseconds:用来设置百分位统计的滚动窗口的持续时间,单位为毫秒。 metrics.rollingPercentile.numBuckets:用来设置百分位统计滚动窗口中使用桶的数量。 metrics.rollingPercentile.bucketSize:用来设置每个“桶”中保留的最大执行数。 metrics.healthSnapshot.intervalInMilliseconds:用来设置采集影响断路器状态的健康快照的间隔等待时间。
5、Request Context:涉及HystrixCommand使用HystrixRequestContext的设置。 requestCache.enabled:用来配置是否开启请求缓存。 requestLog.enabled:用来设置HystrixCommand的执行和事件是否打印到日志的HystrixRequestLog中。
ignoreExceptions
调用服务时,除了HystrixBadRequestException之外,
其他@HystrixCommand修饰的函数抛出的异常均会被Hystrix认为命令执行失败而触发服务降级的处理逻辑(调用fallbackMethod指定的回调函数),
所以当需要在命令执行中抛出不触发降级的异常时来使用它,通过这个参数指定,哪些异常抛出时不触发降级(不去调用fallbackMethod),而是将异常向上抛出。
参考文章
尚硅谷SpringCloud框架开发教程(SpringCloudAlibaba微服务分布式架构丨Spring Cloud)_哔哩哔哩_bilibili
【原创】谈谈服务雪崩、降级与熔断 - 孤独烟 - 博客园 (cnblogs.com)
Hystrix原理与实战_漏水亦凡的专栏-CSDN博客_hystrix
防雪崩利器:熔断器 Hystrix 的原理与使用 - SegmentFault 思否
服务降级和服务熔断_ZERO-CSDN博客_服务熔断和服务降级的区别
什么是服务降级和熔断(网络白话摘要)_sheinenggaosuwo的专栏-CSDN博客_服务降级和服务熔断的区别
@EnableHystrix注解与@EnableCircuitBreaker的区别_是我的温柔啊-CSDN博客_enablecircuitbreaker
Hystrix的Command属性解读_实践求真知-CSDN博客_hystrixcommand