概述
Java 集合接口听得最多的应该就是 List、Queue、Set、Map。
Set 的实现类重要的不多,而且源码也不复杂,甚至觉得没啥可讲的。
这一篇就汇总贴一下源码注释吧,也不过多介绍了: HashSet、TreeSet
还是老规矩,先把源码放上:
- Set 接口源码:https://gitee.com/qianwei4712/JDK1.8.0.25-read/blob/master/src/main/java/java/util/Set.java
- HashSet 源码:https://gitee.com/qianwei4712/JDK1.8.0.25-read/blob/master/src/main/java/java/util/HashSet.java
- TreeSet 源码:https://gitee.com/qianwei4712/JDK1.8.0.25-read/blob/master/src/main/java/java/util/TreeSet.java
Set 接口
首先说下 Set 接口设计的定义:
一个不包含重复元素的容器,即不满足 e1.equals(e2) 条件。
Set 接口的官方注释中有这么一句: 如果允许 null,只允许存在一个 null
作为一个接口,这里就列一下它的方法和设计要求,具体使用在实现类里讲解。
查询操作
| 方法名/参数/返回值 | 接口设计约束 |
|---|---|
int size() | 返回此集合中的元素数。如果此集包含超过 Integer.MAX_VALUE,则返回 Integer.MAX_VALUE。 |
boolean isEmpty() | 如果集合不包含任何元素,则返回 true |
boolean contains(Object o) | 如果此集合包含指定的元素,则返回 true。 更正式地讲,当且仅当此集合包含一个元素 e,使得(o == null?e == null:o 时,才返回 true)。 |
Iterator<E> iterator() | 返回此集合中元素的迭代器。元素以不特定的顺序返回(除非此集合是提供保证的某些类的实例)。 |
Object[] toArray()<T> T[] toArray(T[] a) | 转数组 |
修改操作
| 方法名/参数/返回值 | 接口设计约束 |
|---|---|
| boolean add(E e); | 如果指定的元素尚不存在,则将其添加到该集合(可选操作) 更正式地讲,如果集合中不包含任何元素 e2 ,满足 e == null?e2 == null :e.equals(e2) 如果此集合已经包含元素,则调用将使该集合保持不变,并返回 false 结合构造函数上的限制,可以确保集合永远不会包含重复元素 |
| boolean remove(Object o); | 如果存在指定的元素,则从该集合中删除(可选操作) 更正式地讲,删除元素 e,满足 o == null?e == null:o.equals(e) 如果此集合包含元素,则返回 true(或者等效地,如果此集合作为调用结果更改) 一旦调用返回,此集合将不包含该元素。 |
其他操作
| 方法名/参数/返回值 | 接口设计约束 |
|---|---|
| boolean containsAll(Collection<?> c); | 判断包含全部 |
| boolean addAll(Collection<? extends E> c); | 批量添加 |
| boolean retainAll(Collection<?> c); | 删除差集 |
| boolean removeAll(Collection<?> c); | 删除交集 |
| void clear(); | 删除所有元素,操作后集合为空 |
| boolean equals(Object o); | 两个集合具有相同的大小,指定集合的每个成员都包含在此集合中,则返回 true 此定义确保 equals 方法可在 set 接口的不同实现中正常工作 |
| int hashCode(); | 返回此集合的哈希码值 集合的哈希码定义为集合中元素的哈希码之和,其中 null 元素的哈希码为零。 |
HashSet 源码
HashSet 通过内部维护一个 HashMap 来实现。主要就以下几点:
- 添加到 HashSet 的元素作为 HashMap 的 Key
- 所有 HashMap 的 Value 共用一个 static final 的 new Object
HashMap 源码可以看看以前写过的 : https://blog.csdn.net/m0_46144826/article/details/106300438
实在没什么好讲的,贴下代码略过了。。。。
/**
* 此类实现 Set接口,并由哈希表(实际上是 HashMap实例)支持。
* 它不保证集合的迭代顺序,特别是,它不能保证顺序会随着时间的推移保持恒定。此类允许null元素。<p>
*
* 此类为基本操作提供恒定的时间性能(添加,删除,包含和大小),假设哈希函数将元素正确分散在各个存储桶中。
* 对此集合进行迭代需要的时间与 HashSet实例的大小(元素数)之和加上 HashMap实例的“容量”(数量之和)成比例个桶。
* 因此,如果迭代性能很重要,则不要将初始容量设置得过高(或负载因数过低),这一点非常重要。<p>
*
* <strong>请注意,此实现未同步。</ strong>
* 如果多个线程同时访问 hashset,并且线程中的至少一个修改了哈希集,则必须外部同步。
* 这通常是通过对某些自然封装了该对象的对象进行同步来完成的。<p>
*
* 如果不存在这样的对象,则应使用{@link Collections#synchronizedSet Collections.synchronizedSet} 方法来“包装”该集合。
* 最好在创建时执行此操作,以防止意外异步访问集合:
* <pre> * Set s = Collections.synchronizedSet(new HashSet(...)); </ pre><p>
*
*此类的iterator方法返回的迭代器为<i>fail-fast</ i>:
* 如果在创建迭代器后的任何时间修改了集合,则除通过迭代器自己的remove法外,迭代器将引发{@link ConcurrentModificationException}。<p>
*
* 请注意,不能保证迭代器的快速失败行为,因为通常来说,在存在不同步的并发修改的情况下,不可能做出任何硬性保证。
* 快速失败的迭代器尽最大努力抛出<tt> ConcurrentModificationException </ tt>。
* 因此,编写依赖于此异常的程序的正确性是错误的:<i>迭代器的快速失败行为仅应用于检测错误。</ i>
*
* @param <E> 此集合所维护的元素类型
* @since 1.2
*/
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// 在 HashMap中与key对应的虚拟值,所有 HashSet公用一个
private static final Object PRESENT = new Object();
/**
* 构造一个空的 HashSet,默认HashMap长度16,扩容系数0.75
*/
public HashSet() {
map = new HashMap<>();
}
/**
* 构造一个新集合,其中包含指定集合中的元素。 HashMap是使用默认加载因子(0.75)和足以容纳指定集合中的元素的初始容量创建的。
* @param c 指定添加的集合
* @throws NullPointerException 如果指定集合为空
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* 带默认长度和扩容系数的构造器
* @param initialCapacity hashmap的初始容量
* @param loadFactor hashmap的扩容系数
* @throws IllegalArgumentException 如果扩容系数和初始长度小于0
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* 指定初始容量的构造器,默认扩容系数0.75
* @param initialCapacity 指定初始容量
* @throws IllegalArgumentException 如果初始长度小于0
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
* 构造一个新的空链接哈希集。 (此包private构造函数仅由LinkedHashSet使用。)支持 HashMap实例是具有指定的初始容量和指定的负载因子的LinkedHashMap。
* @param initialCapacity hashmap的初始容量
* @param loadFactor hashmap的扩容系数
* @param dummy 被忽略(将此构造函数与其他int,float构造函数区分开)
* @throws IllegalArgumentException 如果扩容系数和初始长度小于0
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
/**
* 返回此集合中元素的迭代器。直接使用 hashmap的keyset迭代器
* 元素不按特定顺序返回。
* @return set迭代器
* @see ConcurrentModificationException
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
}
/**
* @return 此集合中元素的数量
*/
public int size() {
return map.size();
}
/**
* @return 如果此集合不包含任何元素,则返回 true
*/
public boolean isEmpty() {
return map.isEmpty();
}
/**
* 如果此集合包含指定的元素,则返回 true。
* 更正式地讲,当且仅当此集合包含元素 e,使得(o == null?e == null:o时,才返回 true)。
* @param o 需要进行判定的元素
* @return 如果此集合包含该元素,则返回 true
*/
public boolean contains(Object o) {
return map.containsKey(o);
}
/**
* 如果指定的元素尚不存在,则将其添加到该集合中。
* 因为 hashmap 添加已有的 key,会返回原value,所以不为null。
* @param e 需要添加的元素
* @return 如果原 set不含有该元素,则返回true
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
/**
* 从该集合中删除指定的元素(如果存在)。
* 因为 hashmap 删除某个 key,会返回原value。如果不存在则会返回null。
* @param o 要从此集中移除的对象(如果存在)
* @return 如果此集合包含该元素,则返回 true
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
/**
* 清空
*/
public void clear() {
map.clear();
}
/**
* @return 返回此HashSet的浅拷贝
*/
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
/**
* 将此 HashSet实例的状态保存到流中(即对其进行序列化)。
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out HashMap capacity and load factor
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
// Write out size
s.writeInt(map.size());
// Write out all elements in the proper order.
for (E e : map.keySet())
s.writeObject(e);
}
/**
* 从流中重构 HashSet实例(即反序列化)。
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read capacity and verify non-negative.
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("Illegal capacity: " + capacity);
}
// Read load factor and verify positive and non NaN.
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " + loadFactor);
}
// Read size and verify non-negative.
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("Illegal size: " + size);
}
// Set the capacity according to the size and load factor ensuring that
// the HashMap is at least 25% full but clamping to maximum capacity.
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f), HashMap.MAXIMUM_CAPACITY);
// Create backing HashMap
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
/**
* 在此元素上创建一个可分割迭代器<em> <a href="Spliterator.html#binding"></a> </ em>,实现了快速失败机制<em>fail-fast</ em> {@link Spliterator}。
* @return a {@code Spliterator} over the elements in this set
* @since 1.8
*/
public Spliterator<E> spliterator() {
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
}
}
TreeSet 源码
TreeSet 继承关系
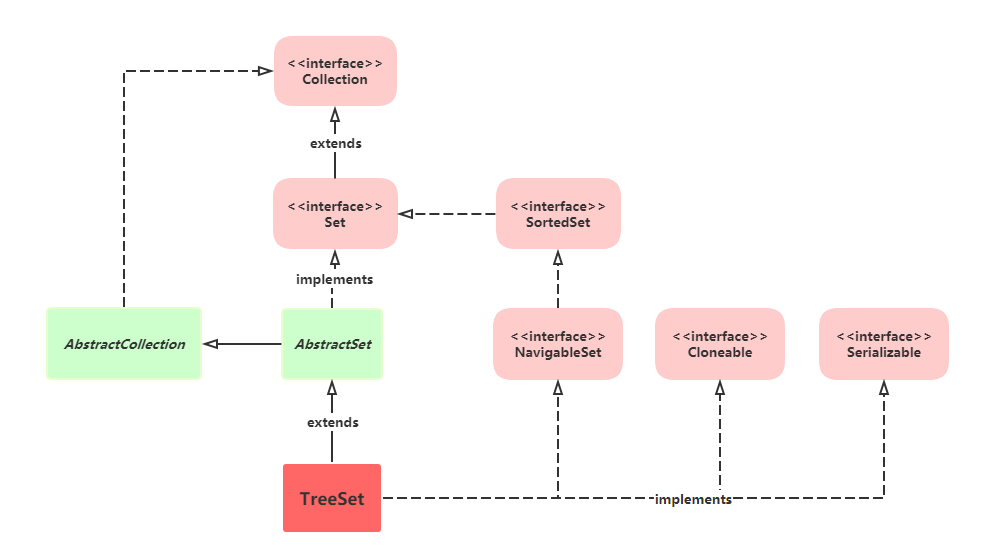
老规矩,稍微说下继承的几个类有啥作用:
实现 Serializable 接口开启序列化功能 ----具体介绍请转 Java 面向对象基础 - 异常、序列化
实现 Cloneable 接口,允许使用 clone() 方法克隆 — 具体介绍请转 Java 面向对象基础 - Object 通用方法
AbstractSet 抽象类提供了 Set 的基础实现,是的 TreeSet 不需要从零开始实现一个 Set 的所有方法。当然,AbstractCollection 也一样。
然后剩下的 NavigableSet 和 SortedSort 实现了元素的比较,确定优先级,后面再详细讲。
SortedSet、NavigableSet
先把代码注释放上:
SortedSet 接口源码 :https://gitee.com/qianwei4712/JDK1.8.0.25-read/blob/master/src/main/java/java/util/SortedSet.java
NavigableSet 接口源码 :https://gitee.com/qianwei4712/JDK1.8.0.25-read/blob/master/src/main/java/java/util/NavigableSet.java
SortedSet 是 NavigableSet 的父类。
SortedSet 是一个自动排序不重复的 Collection 集合,接口设计要求实现一个 comparator 比较器,如果没有实现,则使用元素自带的比较器。
NavigableSet 在 SortedSet 基础上进行了一些功能增强,具体功能见下表:
SortedSet 接口方法:
| 方法、参数、返回值 | 功能介绍 |
|---|---|
Comparator<? super E> comparator() | 返回本 SortedSet 的比较器,如果使用自然排序则返回 null |
SortedSet<E> subSet(E fromElement, E toElement) | 返回此集合部分的视图,其元素范围从(包括)到(不包括)。 |
SortedSet<E> headSet(E toElement) | 此集合的一部分的视图,其元素严格小于 |
SortedSet<E> tailSet(E fromElement) | 此集合中元素大于或等于的部分的视图 |
E first() | 返回当前 set 中第一个(最小)节点 |
E last() | 返回当前 set 中最后(最大)一个节点 |
NavigableSet 接口添加的方法:
| 方法、参数、返回值 | 功能介绍 |
|---|---|
| E lower(E e); | 返回此 set 中严格小于给定元素的最大元素;如果不存在这样的元素,则返回 null。 |
| E floor(E e); | 返回此 set 中小于等于给定元素的最大元素;如果不存在这样的元素,则返回 null。 |
| E ceiling(E e); | 返回此 set 中大于等于给定元素的最小元素;如果不存在这样的元素,则返回 null。 |
| E higher(E e); | 返回此 set 中严格大于给定元素的最小元素;如果不存在这样的元素,则返回 null。 |
| E pollFirst(); | 获取并移除第一个(最小)元素;如果此 set 为空,则返回 null。 |
| E pollLast(); | 获取并移除最后一个(最大)元素;如果此 set 为空,则返回 null。 |
Iterator<E> iterator(); | 以升序返回在此 set 的元素上进行迭代的迭代器。 |
NavigableSet<E> descendingSet(); | 返回此 set 中所包含元素的逆序视图。 |
Iterator<E> descendingIterator(); | 以降序返回在此 set 的元素上进行迭代的迭代器。 |
NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive); | 返回此 set 的部分视图,其元素范围从 fromElement 到 toElement。根据 fromInclusive 和 toInclusive 判断是否包含边界。 |
NavigableSet<E> headSet(E toElement, boolean inclusive); | 返回此 set 的部分视图,其元素范围从开始到 toElement。根据 toInclusive 判断是否包含边界。 |
NavigableSet<E> tailSet(E fromElement, boolean inclusive); | 返回此 set 的部分视图,其元素范围从 fromElement 到结束。根据 fromInclusive 判断是否包含边界。 |
TreeSet 简单介绍
TreeSet 和 HashSet 一样,都是都是通过适配器模式完成。
通过内部维护一个 NavigableMap 来实现。主要就以下几点:
- 添加到 TreeSet 的元素作为 NavigableMap 的 Key
- 所有 NavigableMap 的 Value 共用一个 static final 的 new Object
代码实现其实和上面的 HashSet 一样。。我就不贴了。。
这里顺便提下,TreeSet 使用 NavigableMap 最为参数,而不是 TreeMap 。
很明显的,使用接口作为参数,可以增加程序的扩展性,所有实现接口的类都可以传入。