前言
阅读 Java 版本为 1.8.0.25。
好久没看集合类的源码了,自从看完 Set 类的源码后,就基本结束了这一块。
本来计划是开始阅读 ConcurrentHashMap 之前,先把线程安全部分全部学习完。
不过昨天在别人的博客中看到了 LinkedHashMap 这个类。我发现我居然从来没见过,那就抽一天看下源码。
LinkedHashMap 源码:https://gitee.com/qianwei4712/JDK1.8.0.25-read/blob/master/src/main/java/java/util/LinkedHashMap.java

使用场景
首先,在官方 Java doc 中写到了:
那么啥是 LRU缓存机制 呢???
LRU 是 Least Recently Used 的缩写,即最近最少使用,是一种常见的页面置换算法。该算法的思路是,发生缺页中断时,选择未使用时间最长的页面置换出去。 ------- 百度百科
那个这样, LRU缓存机制 也就很好理解了。
虽然我现在还没开始看代码,Linked 在 Java 中表示链表 ,这是众所周知的,盲猜应该是:
好了,到底是不是这样,就从下面开始讲解主要源码。

LinkedHashMap 参数属性
LinkedHashMap 继承了 HashMap ,还实现了 Map 接口(虽然不知道这一步实现有啥意义)。
关于 HashMap ,呃,讲道理的话,都看 LinkedHashMap 了,不可能没看过 HashMap 。
但还是贴一下以前写的 HashMap 源码解读:侃晕面试官的 HashMap 源码分析 - 这真不是我吹
好嘞,下面正式开始。。。。

字段属性
LinkedHashMap 的底层实现也很简单,基本的功能都是继承自 HashMap :
/**
* 双向链表的头(最老的节点)。
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* 双向链表的尾(最新的节点)。
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* 此链接的哈希映射的迭代排序方法: true-访问顺序, false-插入顺序
*/
final boolean accessOrder;
一看参数基本就知道它的结构了,链表头尾两个指针引用 ,基本确定这是双向链表 。
accessOrder 的注释也很明确的说明了,这个链表的访问顺序可以有两种:
- 访问顺序表示 :把访问过的元素放在链表最后,遍历的顺序会随访问而变化
- 插入顺序表示 :直接按照插入的顺序
其次是链表底层节点,直接继承了 HashMap.Node :
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
static class Node<K,V> implements Map.Entry<K,V> {
//节点hash值
final int hash;
final K key;
V value;
//下一个节点引用
Node<K,V> next;
}
因此自带 Node 最基础和常用的属性,包括: hash、key、value ,再加上继承后新增的 before、after 两个前后引用,就可以实现链表节点的基本功能。
构造方法
使用 HashMap 时,一般都是直接使用默认无参构造方法。
但是 LinkedHashMap 具有 访问顺序 和 插入顺序 的模式选择,所以,在构造时推荐带有模式参数的构造方法:
/**
* @param initialCapacity 初始容量
* @param loadFactor 扩容系数
* @param accessOrder 排序模式- true用于访问顺序, false用于插入顺序
* @throws IllegalArgumentException 如果初始容量或负载系数为负
*/
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
顺便,影响 HashMap 性能的参数就是 初始长度和扩容系数 ,这两个参数同样对 LinkedHashMap 性能也有影响。
扩容系数又成为负载因子,负载因子越大表示散列表的装填程度越高。
对于哈希表来说,如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;
如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
当然负载因子的计算离不开哈希表长度,所以这两个参数是影响 hashmap 性能的参数。
功能实现原理
还是推荐看完 HashMap 源码,对于这些本文基本不会过多:侃晕面试官的 HashMap 源码分析 - 这真不是我吹
LinkedHashMap 没有重写 put 方法,所以添加元素依然是按照 HashMap ,哈希桶的方式。

这不对啊,刚刚不是说好了链表形式嘛??
难道是物理上的哈希桶,逻辑上的链表?
从 put 开始测试
先来做个测试,当然是测试访问模式:
public void test1(){
LinkedHashMap<Integer, Integer> map = new LinkedHashMap<>(16, 0.75f, true);
for (int i = 0; i < 5; i++) {
map.put(i, i);
}
map.get(3);
map.put(7, 7);
map.get(2);
map.forEach((s, s2) -> System.out.print(s + ", "));
}
输出结果:
0, 1, 4, 3, 7, 2,
但是在 HashMap 结构下,这个链表结构是如何实现的呢?
说实话,想到这个问题我真的有点懵,明明 LinkedHashMap 没有重写 put,为什么还有链表相连呢?
不死心回过头去看 HashMap 的 put 方法,居然发现有这么一个玩意儿:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
.......
// 现有键映射,说明该 key已经存在
if (e != null) {
//拿到原有值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//回调操作,在 HashMap 中无效
afterNodeAccess(e);
return oldValue;
}
.......
//回调操作,在 HashMap 中无效
afterNodeInsertion(evict);
......
}

在 HashMap 上创建链表
先看 afterNodeAccess 方法代码,看名称就知道这个方法代表 访问后回调 :
// 访问后回调,将节点移到最后面
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
// 如果遍历顺序是访问顺序(accessOrder = true)
// 并且当前最后一个节点指针并不是该节点
if (accessOrder && (last = tail) != e) {
// 获得节点以及前后节点的引用
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//将下一个节点引用设置为null(意思就是打算放在链表最后)
p.after = null;
// 如果原本的上一个节点为空,说明当前节点是第一个节点
if (b == null) head = a;
else b.after = a; //否则将上一个和下一个进行相连
// 如果原本的下一个节点不为空,将上一个和下一个进行相连
if (a != null) a.before = b;
else last = b; //否则先暂存最后一个节点索引为 before
//最后将该节点连到最后
if (last == null) head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;//快速失败机制标志位 +1
}
}
如果在 LinkedHashMap 中添加如下节点:
@Test
public void test2(){
int[] datas = {10, 2, 24, 18, 34};
LinkedHashMap<Integer, Integer> map = new LinkedHashMap<>(16, 0.75f, true);
for (int data : datas) {
map.put(data, data);
}
map.forEach((s, s2) -> System.out.print(s + ", "));
}
那么,在 LinkedHashMap 中,它的结构是这样的
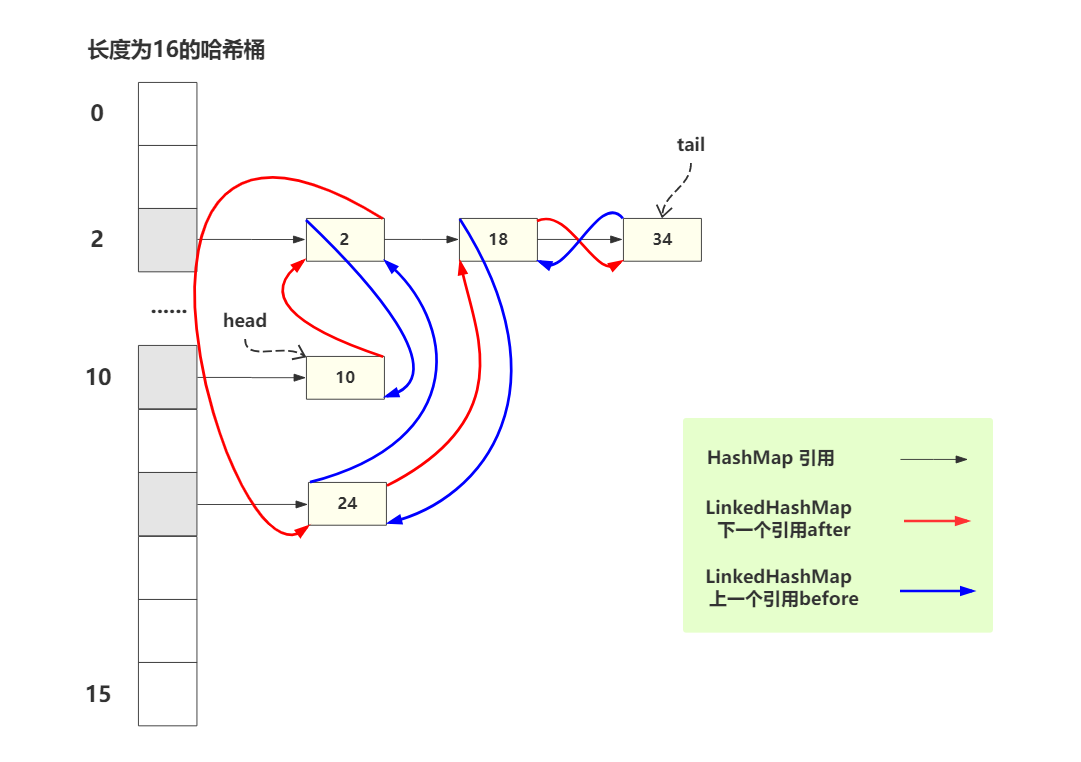
看起来如果有点乱,可以把链表抽取出来
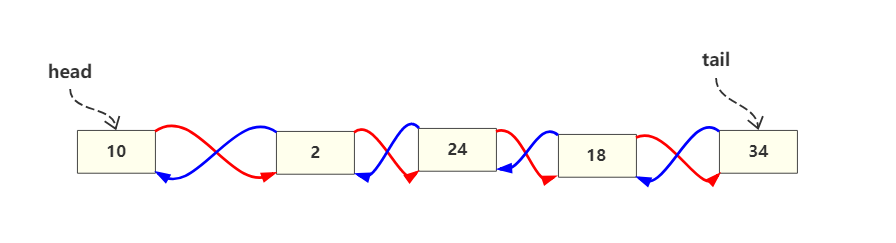
可以发现,其实就是一个双向链表。
所以 LinkedHashMap 其实就是在 HashMap 基础上,再加一个链表。
缓存移除最旧的元素
再看 afterNodeInsertion 方法代码注释如下:
/**
* 可能删除最旧的节点
* @param evict 如果为false,则 hashmap 表处于构造阶段
*/
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
// evict参数不需要管,这是在 HashMap 中就确定的
// 获得第一个节点引用,第一个节点不为null,并且链表断开第一个节点,更改 head 引用
// 最后才移除节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
// 移除第一个节点
removeNode(hash(key), key, null, false, true);
}
}
逻辑也非常简单,其实就是在添加节点后弄一个回调。
然后主要的断开链接的方法 removeEldestEntry ,原生代码如下:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
在 JDK 中,默认返回 false。也就是说默认是不进行删除操作的。
在该方法的 java doc 上就给出了使用示例,现在我给补全下:
public class LinkedHashMapTest<K, V> extends LinkedHashMap<K, V>{
private static final int MAX_ENTRIES = 100;
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > MAX_ENTRIES;
}
}
同样的,在移除节点是,进行了移除回调 afterNodeRemoval ,步骤和访问类似。
// 删除节点回调,解除相连
void afterNodeRemoval(Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
get 访问激活节点
LinkedHashMap 的官方注释上写到了这么一句:
所以如果使用了访问模式(accessOrder 为 true),那么在调用 get 时,就会对原有链表进行修改。
还是调用访问回调,在上文中已经介绍了变化过程。
/**
* 返回指定键所映射到的值;如果此映射不包含键的映射关系,则返回或{@code null}。
* <p>返回值 null 不一定表示映射不包含该键的映射;
* 映射也可能显式地将密钥映射到 null。
* {@link #containsKey containsKey}操作可用于区分这两种情况。
*/
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
哦,这里特别的要说明下,因为 LinkedHashMap 允许 null 作为 key 和 value .
所以如果 get 返回结果为 null 时,需要特别关注。
参考文章
https://baike.baidu.com/item/LRU/1269842
https://www.pdai.tech/md/java/collection/java-map-LinkedHashMap&LinkedHashSet.html