垃圾回收概述
终于学到垃圾回收(Garbage Collection)了。。。把这部分干掉,后面的就是调优了。。。
总算要把 JVM 部分搞完了。。

好嘞,开始开始,gogogo
首先,第一个问题是:
JVM 中,什么是垃圾?
垃圾是指在 ,这些对象需要被回收。

然后,第二个问题是:
JVM 为什么需要 GC ?
这个问题的解答,可以很复杂,也可以很简单。
- 在运行时数据区篇中,已经初步对 GC 的作用进行了介绍。不论年轻代、老年代还是现在基于直接内存的元空间,大小都是有限的。如果不对垃圾进行回收,时间一长肯定会造成内存移除。
- 除了释放没用的对象,GC 也可以清理内存里的记录碎片。碎片整理将所占用的堆内存一刀堆的一端,以便 。
垃圾回收相关算法
上面说了,垃圾回收是 JVM 回收运行程序中没有任何指针指向的对象。
所以这里分为两步,它们涉及的算法如下:
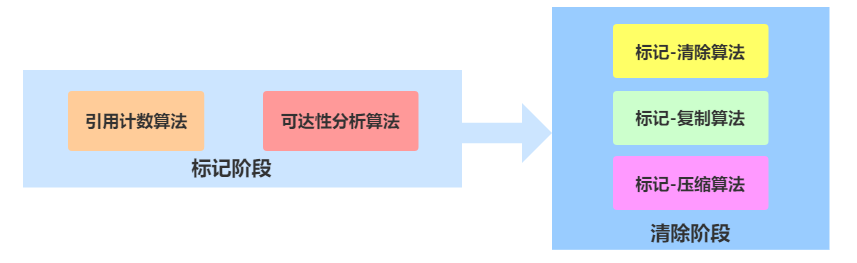
标记阶段,标记的是被引用的对象;清除阶段,清除的是未被标记的对象。
标记阶段
垃圾标记阶段,目的是为了判断对象是否存活。
在运行时数据区篇,已经介绍过:存在 GC 的只有堆和方法区。
这块空间内,GC 的频率大小排序为:年轻代 > 老年代(较少进行 GC)> 元空间(基本不进行 GC)
所以年轻代和老年代是 GC 的重点区域,而这两个区域存放的是 new 创建的对象。
标记阶段的算法有 引用计数算法 和 可达性分析算法 ,但是引用分析算法是不被考虑的。

不被考虑的也得学啊,毕竟面试要问啊。。。
引用计数算法
引用计数算法很好理解:
存在一个引用计数就加一,引用失效就减一;当计数值为 0 时,表示没有被引用,就可以进行回收。
比如如下循环链表的示意图:
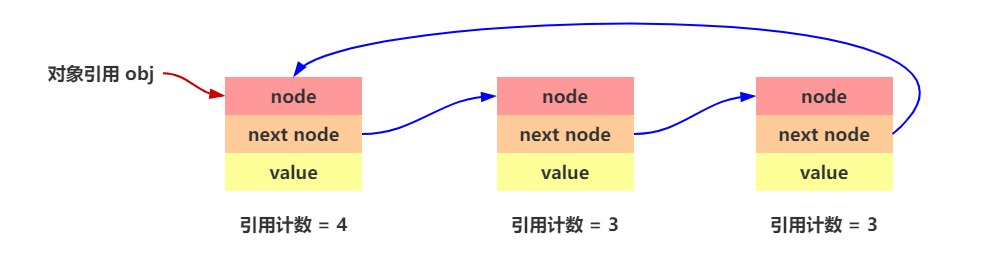
这个算法的优点非常明显:
- 实现简单,垃圾对象便于辨别;
- 判定效率高,回收没有延迟性。就是不需要 STW 停下所有用户线程。
当然,不存在完美的算法,它的缺点是:
- 它需要单独的字段存储计数器,这样的做法 增加了存储空间的开销 。
- 每次赋值都需要更新计数器,伴随着加法和减法操作,这 增加了时间开销 。
- 引用计数器有一个严重的问题,即无法处理循环引用的情况。这是一条致命缺陷,导致在 Java 的垃圾回收器中没有使用这类算法。
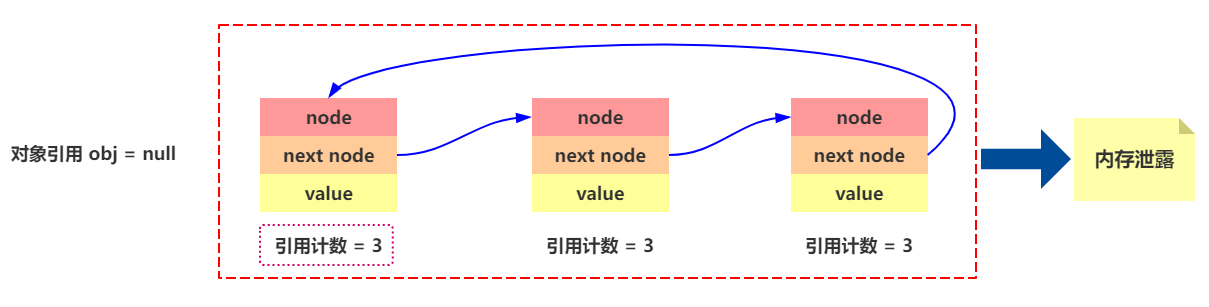
内存泄露,简单来说就是 应该回收的对象没有进行回收 。
呃,这个看个热闹就好了。。。Java 中并不会用这个算法。。。所以算是扩展下知识而已。。。。。
可达性分析算法
可达性分析算法,又可以称为根搜索算法、追踪性垃圾收集算法。
这个算法解决了引用计数算法的循环引用问题,这个算法也是 Java 所选择的算法。
它的实现基本原理如下:
- 维护一个
GC Roots根集合,它是一组活跃的引用; - 可达性分析算法以根对象集合
GC Roots为起点,按照从上而下的方式 ; - 使用可达性分析算法后,内存中的存活对象都会被
GC Roots直接或间接得链接着,搜索走过的路径称为 引用链(Reference Chain) ; - 如果目标对象没有任何引用链相连,则是不可达,就意味着对象已经死亡,可以被标记为垃圾;
- 只有能够被根对象直接或间接相连的对象才是存活对象。

全是视频里讲的,写一遍感觉有点水。。。
上面可以看出 GC Roots 根集合是垃圾判定的关键,所有 GC Roots 根集合到底包含了哪些引用?
虚拟机栈引用的对象,比如:各个线程被调用的方法中使用到的参数、局部变量等;
本地方法栈内的引用对象;
类静态属性引用的对象、常量引用对象(例如:字符串常量池);
所有被同步锁持有的对象;
Java 虚拟机内部引用。基本数据类型对应的 Class 对象,一些常驻异常对象(空指针对象、OOM 对象)、系统类加载器。
特殊的还有:分代收集和局部回收器,可能会临时性加入。
finalize() 方法
在进入清除阶段前,先介绍下 Object.finalize() 方法。
Object.finalize() 是 Object 自带的类,所有对象回收都会调用这个方法,这个方法开发人员提供了对象被销毁之前的自定义逻辑。
protected void finalize() throws Throwable {}
从它的代码可以发现,它是一个非 private、final 的方法,可以被重写。
一般可以用在关闭文件、资源释放的场景下。
不要主动调用 Object.finalize() 方法,原因如下:
- 调用
Object.finalize()方法,可能会导致对象复活; finalize()方法的执行时间是没有保障的,它完全由 GC 线程决定,而这个线程优先级很低。极端情况下,若不发生 GC ,则finalize()方法将没有执行的机会;- 糟糕的
finalize()会影响 GC 的性能,例如:方法内发生死循环。
由于 Object.finalize() 方法的存在,JVM 中的对象存在三种状态:
- 可触及的:从根节点出发,可以到达这个对象;
- 可复活的:对象的所有引用都被释放,但是对象有可能在
finalize()方法中复活; - 不可触及的:对象的
finalize()方法被调用,并且没有复活,那么进入不可触及状态。finalize()方法只能被调用一次,随意这个对象不存在再复活的机会。

写段代码,举个例子先。。。
public class ReliveTest {
/**
* static 引用属于 GC Roots
*/
public static ReliveTest obj;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用 finalize 方法;");
obj = this;
}
public static void TestAlive(){
if (obj == null){
System.out.println("static 引用不存在,对象已经死亡");
}else {
System.out.println("static 引用仍然存在,对象在finalize方法中复活");
}
}
}
测试方法如下:
public static void main(String[] args) throws InterruptedException {
obj = new ReliveTest();
obj = null;// 将 static 引用置空
System.gc();// 主动调用 GC,无法保证 GC 什么时候发生
Thread.sleep(5000);// 因为 Finalizer 线程优先级很低,多暂停几秒
TestAlive();
//第二次调用
obj = null;
System.gc();
Thread.sleep(5000);
TestAlive();
}
执行结果:
调用 finalize 方法;
static 引用仍然存在,对象在finalize方法中复活
static 引用不存在,对象已经死亡
呃。结合上面的原理,其实比较简单,不详细解释了。。
清除阶段
清除阶段也分为不同的清除形式,也存在未被选用的算法。
| 标记-清除算法 | 复制算法 | 标记-压缩算法 | |
|---|---|---|---|
| 速度 | 中等 | 最快 | 最慢 |
| 空间开销 | 少,但是会堆积碎片 | 需要两倍的内存空间,但不堆积碎片 | 少,并且不会堆积碎片 |
| 移动对象 | 不会 | 会 | 会 |
从算法角度来说,时间复杂度是最主要的考虑因素。在各个内存结构中,要根据各自的特点进行使用。
这也就是 分代收集 的核心思想。
标记-清除算法
执行原理如下:
- 当堆中的有效内存空间被耗尽的时候,就会启动 STW。然后进行两项工作,第一项则是标记,第二项则是清除。
- 标记阶段: Collector 从引用根节点开始遍历,标记所有被引用的对象。一般是在对象的 Header 中记录为可达对象。
- 清除阶段: Collector 对堆内存从头到尾进行线性的遍历,如果发现某个对象在其 Header 中没有标记为可达对象,则将其回收。
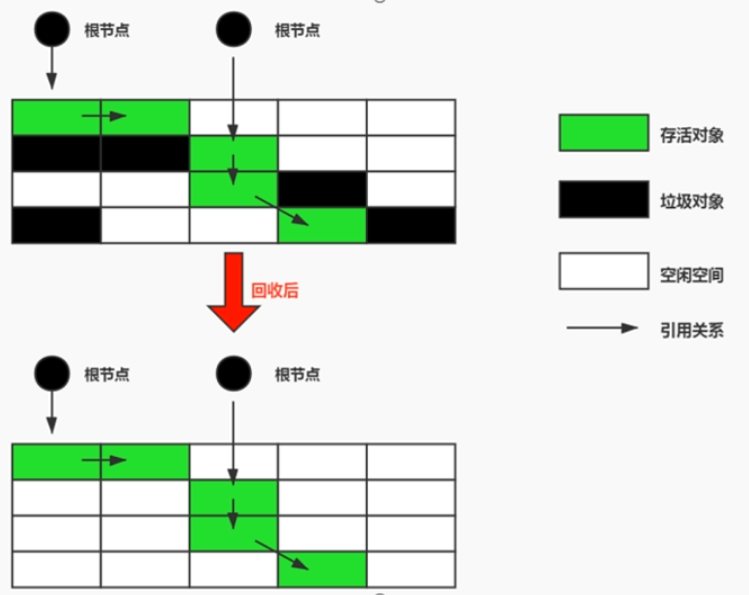
这种算法是比较原始的清除算法,它存在很明显的缺点:
- 这种方式清理出来的内存是不连续的,产生内存碎片。需要维护一个空闲列表来管理这些内存碎片,产生额外消耗。
- 如果产生太多的内存碎片,导致大对象没有联系的空间进行分配,就会产生 OOM。
标记-复制算法
标记-复制算法在 JVM 中存在很明显的案例,在运行时数据区有过简单的介绍。
年轻带中的 Survivor 0 和 1 区就是使用标记-复制算法,在 From 区和 to 区相互复制还存活的对象。
详情请进入传送门:JVM 运行时数据区 - 多图预警、万字内存模型解读
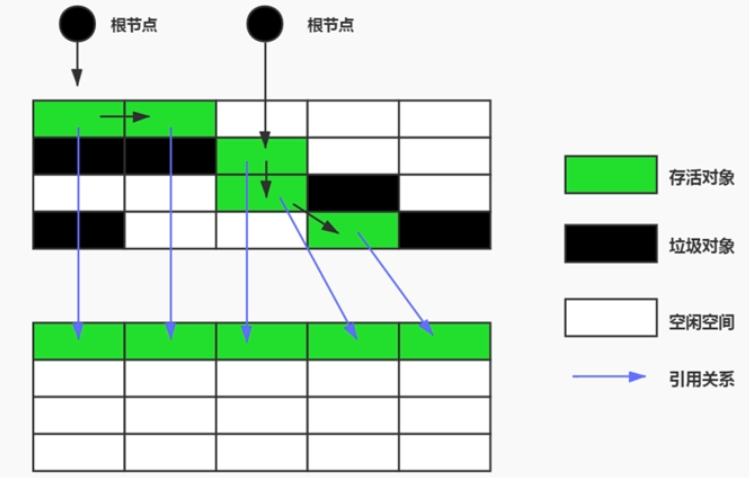
这种算法也有比较明显的特点和使用场景,简要如下:
- 和原来对比,需要使用双倍的内存空间;
- 复制之后内存空间是连续的,不会存在碎片问题;
- 复制之后,对象的实际地址发生了变化,栈空间内引用地址也需要同步更新,额外产生了消耗;
- 特别适合垃圾对象很多,存活对象很少的场景。这种场景适用于新生代,不适用于老年代。
标记-压缩算法
相比于标记-复制算法,标记-压缩算法更加适用于 GC 次数少的老年代。
标记-压缩算法效果类同于 标记-清除-压缩 三个步骤,在标记-清除算法的基础上,再进行一次内存整理,清除碎片。
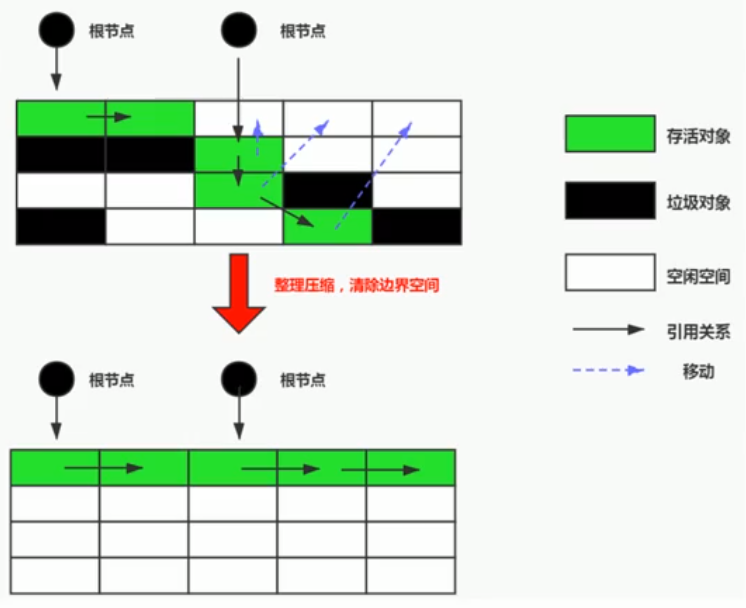
这个算法解决了标记-清除算法和标记-复制算法的缺点,但是效率要更低点。
其他算法
增量收集算法
伴随 GC 的 STW 是程序性能最大的敌人,原本的垃圾收集是针对整个内存空间,或者说是整个分带区域进行收集,这样大区域的收集会增加 STW 的时间,影响用户体验。
所以,增量收集算法的核心思想就是:
每次垃圾收集线程只收集一小片区域的内存空间,接着切换到应用程序线程。依次反复,直到垃圾收集完成。
这样的方式看起来就造成了延迟降低。
当然,缺点就是间接性得执行应用程序,频繁切换造成垃圾回收总体成本上升,造成系统吞吐量降低。
分区算法
一般来说,在相同条件下,堆空间越大,一次 GC 时所需要的时间就越长,有关 GC 产生的停顿也越长。
为了更好地控制 GC 产生的停顿时间,将一块大的内存区域分割成多个小块,根据目标的停顿时间,每次合理地回收若干个小区间,而不是整个堆空间,从而减少一次 GC 所产生 的停顿。
分代算法将按照对象的生命周期长短划分成两个部分,分区算法将整个堆空间划分成连续的不同小区间。
每一个小区间都独立使用,独立回收。这种算法的好处是可以控制一次回收多少个小区间。
垃圾回收相关概念
在介绍垃圾回收器之前,需要先介绍几个概念,为最后一部分垃圾回收器做准备。
下面看看这些概念性的描述:
- 关于引用的话,可以看看以前学习的:弱引用是什么,和其他引用有啥区别?
- 内存溢出 OOM:没有空间内存,并且垃圾回收也无法提供更多内存。
- 内存泄露:
- 严格来说,只有对象不会再被程序用到了,但是 GC 又不能回收他们的情况,才叫内存泄漏。
- 但实际情况很多时候一些不太好的实践(或疏忽)会导致对象的生命周期变得很长甚至导致 OOM,也可以叫做宽泛意义上的内存泄漏。
- 常见的有单例模式引用其他对象、IO 未关闭、socket 未关闭、数据库连接未关闭。
- 安全点(Safe Point):
- 程序执行时并非在所有地方都能停顿下来开始 GC, 只有在特定的位置才能停顿下来开始 GC,这些位置称为“安全点(Safe Point) ”
- Safe Point 的选择很重要,如果太少可能导致 GC 等待的时间太长,如果太频繁可能导致运行时的性能问题。
- 大部分指令的执行时间都非常短暂,通常会根据 “是否具有让程序长时间执行的特征” 为标准。比如:选择一些执行时间较长的指令作为 Safe Point,如方法调用、循环跳转和异常跳转等。
- 安全区域(Safe Region):
- 安全区域是指在一段代码片段中,对象的引用关系不会发生变化,在这个区域中的任何位置开始 GC 都是安全的。我们也可以把 Safe Region 看做是被扩展了的 Safe Point。
- 当线程运行到 Safe Region 的代码时,首先标识已经进入了 Safe Region , 如果这段时间内发生 GC,JVM 会忽略标识为 Safe Region 状态的线程。
- 当线程即将离开 Safe Region 时,会检查 JVM 是否已经完成 GC,如果完成了,则继续运行,否则线程必须等待直到收到可以安全离开 Safe Region 的信号为止。
